AI Web Scraper - Powered by Crawl4AI
Pricing
$8.00 / 1,000 results
AI Web Scraper - Powered by Crawl4AI

A blazing-fast AI web scraper powered by Crawl4AI. Perfect for LLMs, AI agents, AI automation, model training, sentiment analysis, and content generation. Supports deep crawling, multiple extraction strategies and flexible output (Markdown/JSON). Seamlessly integrates with Make.com, n8n, and Zapier.
1.0 (1)
Pricing
$8.00 / 1,000 results
6
Total users
178
Monthly users
38
Runs succeeded
>99%
Issues response
1.1 hours
Last modified
3 months ago
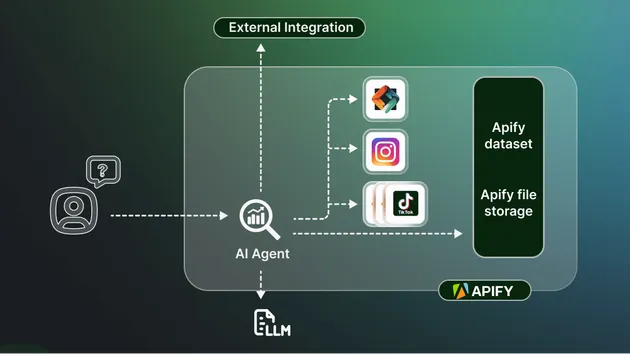
You can access the AI Web Scraper - Powered by Crawl4AI programmatically from your own applications by using the Apify API. You can also choose the language preference from below. To use the Apify API, you’ll need an Apify account and your API token, found in Integrations settings in Apify Console.
$echo '{< "startUrls": [< {< "url": "https://www.cnbc.com/2025/03/12/googles-deepmind-says-it-will-use-ai-models-to-power-physical-robots.html"< }< ],< "browserConfig": {< "browser_type": "chromium",< "headless": true,< "verbose_logging": false,< "ignore_https_errors": true,< "user_agent": "random",< "proxy": "",< "viewport_width": 1280,< "viewport_height": 720,< "accept_downloads": false,< "extra_headers": {}< },< "crawlerConfig": {< "cache_mode": "BYPASS",< "page_timeout": 20000,< "simulate_user": true,< "override_navigator": true,< "magic": true,< "remove_overlay_elements": true,< "delay_before_return_html": 0.75,< "wait_for": "",< "screenshot": false,< "pdf": false,< "enable_rate_limiting": false,< "memory_threshold_percent": 90,< "word_count_threshold": 200,< "css_selector": "",< "excluded_tags": [],< "excluded_selector": "",< "only_text": false,< "prettify": false,< "keep_data_attributes": false,< "remove_forms": false,< "bypass_cache": false,< "disable_cache": false,< "no_cache_read": false,< "no_cache_write": false,< "wait_until": "domcontentloaded",< "wait_for_images": false,< "check_robots_txt": false,< "mean_delay": 0.1,< "max_range": 0.3,< "js_code": "",< "js_only": false,< "ignore_body_visibility": true,< "scan_full_page": false,< "scroll_delay": 0.2,< "process_iframes": false,< "adjust_viewport_to_content": false,< "screenshot_wait_for": 0,< "screenshot_height_threshold": 20000,< "image_description_min_word_threshold": 50,< "image_score_threshold": 3,< "exclude_external_images": false,< "exclude_social_media_domains": [],< "exclude_external_links": false,< "exclude_social_media_links": false,< "exclude_domains": [],< "verbose": true,< "log_console": false,< "stream": false< },< "deepCrawlConfig": {< "max_pages": 100,< "max_depth": 3,< "include_external": false,< "score_threshold": 0.5,< "filter_chain": [],< "keywords": [< "crawl",< "example",< "async",< "configuration"< ],< "weight": 0.7< },< "markdownConfig": {< "ignore_links": false,< "ignore_images": false,< "escape_html": true,< "skip_internal_links": false,< "include_sup_sub": false,< "citations": false,< "body_width": 80,< "fit_markdown": false< },< "contentFilterConfig": {< "type": "pruning",< "user_query": "",< "threshold": 0.45,< "min_word_threshold": 5,< "bm25_threshold": 1.2,< "apply_llm_filter": false,< "semantic_filter": "",< "word_count_threshold": 10,< "sim_threshold": 0.3,< "max_dist": 0.2,< "top_k": 3,< "linkage_method": "ward"< },< "userAgentConfig": {< "user_agent_mode": "random",< "device_type": "desktop",< "browser_type": "chrome",< "num_browsers": 1< },< "llmConfig": {< "provider": "groq/deepseek-r1-distill-llama-70b",< "api_token": "",< "instruction": "Summarize content in clean markdown.",< "base_url": "",< "chunk_token_threshold": 2048,< "apply_chunking": true,< "input_format": "markdown",< "temperature": 0.7,< "max_tokens": 4096< },< "extractionSchema": {< "name": "Custom Extraction",< "baseSelector": "div.article",< "fields": [< {< "name": "title",< "selector": "h1",< "type": "text"< },< {< "name": "link",< "selector": "a",< "type": "attribute",< "attribute": "href"< }< ]< }<}' |<apify call raizen/ai-web-scraper --silent --output-datasetAI Web Scraper - Crawl4AI for LLMs, AI Agents & Automation API through CLI
The Apify CLI is the official tool that allows you to use AI Web Scraper - Powered by Crawl4AI locally, providing convenience functions and automatic retries on errors.
Install the Apify CLI
$npm i -g apify-cli$apify loginOther API clients include: