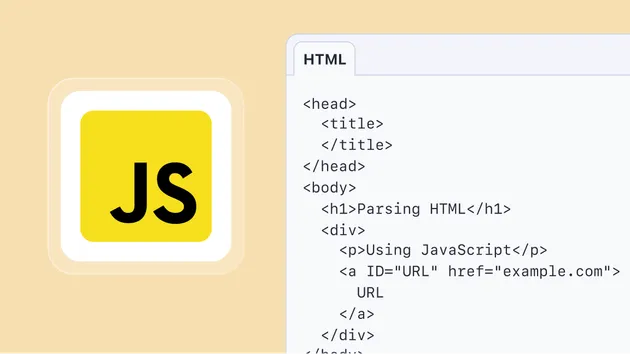
Download HTML from URLs
Pricing
Pay per usage
Go to Store
Download HTML from URLs

This actor takes a list of URLs and downloads HTML of each page.
0.0 (0)
Pricing
Pay per usage
25
Total users
8.6K
Monthly users
93
Runs succeeded
>99%
Last modified
a year ago
Proxy configuration
proxyConfigurationobjectRequired
Choose to use no proxy, Apify Proxy, or provide custom proxy URLs.
Default value of this property is {}
Page timeout
handlePageTimeoutSecsintegerOptional
Maximum time the scraper will spend processing one page.
Default value of this property is 60