DataDome Web Scraper
Pricing
$20.00/month + usage
DataDome Web Scraper

DataDome Web Scraper extracts data from DataDome-protected websites. You can customize parameters such as proxies, timeouts, and JavaScript execution, making it ideal for reports, spreadsheets, and applications.
0.0 (0)
Pricing
$20.00/month + usage
0
Total users
17
Monthly users
3
Runs succeeded
>99%
Last modified
9 days ago
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
What does Datadome web Scraper do?
Introduction
Datadome is one of the most sophisticated bot protection systems available today, designed to stop automated traffic while allowing genuine users to browse freely. With its ability to process 5 trillion+ signals per day and achieve 99.99% accuracy in distinguishing bots from humans, Datadome presents a significant challenge for legitimate data collection needs.
However, businesses often require access to publicly available data from Datadome-protected websites for market research, competitive analysis, and business intelligence. This data is legally accessible as long as scraping rates remain reasonable and don't impact website performance. Our Datadome Web Scraper addresses this need by providing a reliable solution to bypass Datadome protection while maintaining ethical data collection practices.
Whether you're analyzing marketplace data from platforms like Etsy with over 4 million sellers and 60 million products, conducting competitor research, or gathering market insights, this scraper enables seamless data extraction from Datadome-protected websites.
Scraper Overview and Key Features
The Datadome Web Scraper is an advanced data extraction tool specifically engineered to overcome Datadome's sophisticated bot detection mechanisms. Unlike traditional scrapers that struggle with Datadome's AI-powered behavior analysis and CAPTCHA challenges, our solution employs multiple bypass techniques to ensure consistent data collection.
Core Capabilities:
- Intelligent CAPTCHA Bypass: Automatically handles Datadome CAPTCHA challenges without manual intervention
- Residential Proxy Integration: Uses high-quality residential proxies to mimic genuine user traffic patterns
- Advanced Anti-Detection: Implements browser fingerprinting evasion and behavioral mimicry
- JavaScript Execution: Full support for dynamic content rendering and custom script execution
- Retry Logic: Configurable retry mechanisms to handle temporary blocks or rate limiting
- Geographic Targeting: Proxy selection based on target market location for optimal success rates
Target Users:
- E-commerce businesses conducting competitive analysis
- Market researchers requiring pricing and product data
- Digital marketing agencies tracking competitor activities
- Data analysts studying marketplace trends
- Business intelligence professionals gathering market insights
The scraper is particularly effective for extracting data from e-commerce platforms, search results pages, and product listings where Datadome protection is commonly implemented.
Input and Output Specifications
Example url: https://www.etsy.com/market/top_sellers?ref=pagination&page=3
Example url: https://www.pokemoncenter.com/
Example Screenshot of product information page:
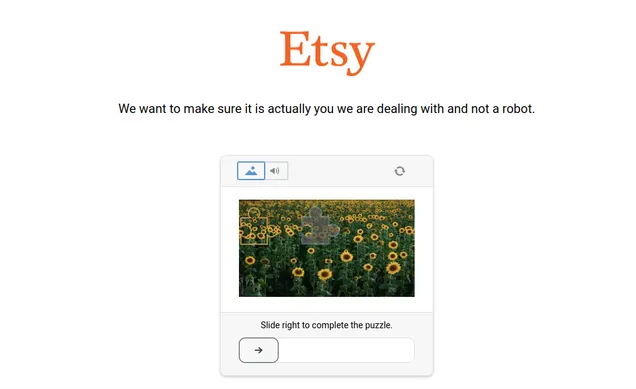
Input Format
The scraper accepts JSON configuration with the following parameters:
Input Parameters Explained:
- max_retries_per_url: Controls the maximum number of retry attempts for each URL when encountering blocks or timeouts. Higher values increase success rates but extend execution time.
- proxy.useApifyProxy: Enables residential proxy rotation to avoid IP-based detection by Datadome's systems.
- proxy.apifyProxyGroups: Specifies proxy type - "RESIDENTIAL" proxies provide the highest success rate against Datadome.
- proxy.apifyProxyCountry: Geographic location of proxies should match your target market for optimal performance.
- urls: Array of target URLs to scrape. Each URL will be processed with the same configuration parameters.
- js_script: Custom JavaScript code to execute on each page, useful for interacting with dynamic content or extracting specific data.
- js_timeout: Maximum execution time for JavaScript scripts to prevent hanging operations.
- retrieve_result_from_js_script: When true, captures and returns the result of your custom JavaScript execution.
- page_is_loaded_before_running_script: Ensures complete page loading before script execution for accurate data extraction.
- execute_js_async: Controls JavaScript execution mode - synchronous execution provides more predictable results.
- retrieve_html_from_url_after_loaded: Captures the complete HTML content after all dynamic elements have loaded.
Output Format
You get the output from the Datadome web Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
The scraper returns structured data containing:
Primary Output Fields:
-
URL: The exact URL that was scraped, useful for tracking and data organization
- Purpose: Enables data source verification and batch processing tracking
- Example:
"https://www.etsy.com/market/top_sellers?ref=pagination&page=3"
-
HTML: Complete HTML content of the scraped page after JavaScript execution
- Purpose: Contains all page data for parsing product information, pricing, descriptions, and metadata
- Usage: Parse with HTML parsers to extract specific elements like product titles, prices, seller information, ratings, and availability
- Data richness: Includes both static HTML and dynamically loaded content
-
Result from JS Script: Output from your custom JavaScript execution
- Purpose: Provides processed data or specific calculations performed on the target page
- Example applications: Product count calculations, price comparisons, availability checks, or custom data transformations
- Format: Can return strings, numbers, objects, or arrays depending on your script logic
The HTML output typically contains rich marketplace data including product information, descriptions, listed dates, images, seller info, pricing, and customer reviews that can be parsed for comprehensive market analysis.
Usage Guide
Step 1: Configuration Setup Configure your input parameters based on your target website and data requirements. For Datadome-protected sites, always use residential proxies and match the proxy country to your target market.
Step 2: URL Preparation Prepare your target URLs ensuring they represent the specific pages containing your desired data. For marketplace scraping, this might include product listings, search results, or seller pages.
Step 3: JavaScript Customization Write custom JavaScript for data extraction or page interaction. This is particularly useful for extracting hidden JSON data embedded in pages rather than parsing HTML elements.
Step 4: Execution and Monitoring Run the scraper and monitor retry attempts. The built-in retry logic handles temporary blocks, but persistent failures may require proxy rotation or rate limiting adjustments.
Best Practices:
- Use reasonable delays between requests to avoid triggering additional protection layers
- Implement data validation to ensure extracted information meets quality standards
- Maintain reasonable scraping rates to avoid impacting website performance
- Regularly rotate proxy locations and user agents for sustained access
Common Issue Resolution:
- If experiencing high block rates, reduce request frequency and increase retry attempts
- For JavaScript timeout errors, increase the js_timeout parameter
- When facing persistent CAPTCHAs, verify proxy quality and geographic alignment
Benefits and Applications
Time Efficiency: Automated data collection eliminates manual browsing and data entry, reducing research time from hours to minutes for large datasets.
Business Intelligence: Extract competitor pricing strategies, product assortments, and marketing techniques to maintain competitive advantage. Build comprehensive databases for market analysis and customer research.
Market Research: Identify trending products through search results analysis and keyword research. Monitor marketplace dynamics, seasonal trends, and emerging opportunities.
Competitive Analysis: Track competitor product launches, pricing changes, and inventory levels across multiple platforms simultaneously.
Scalable Data Collection: Process thousands of URLs efficiently with built-in retry logic and proxy rotation, enabling enterprise-level data gathering operations.
Real-World Applications:
- E-commerce price monitoring and dynamic pricing strategies
- Product development insights from customer reviews and feedback analysis
- Market penetration analysis for new business ventures
- Supply chain optimization through seller and product availability tracking
Conclusion
The Datadome Web Scraper provides a robust solution for accessing valuable business data from protected websites while maintaining ethical scraping practices. By combining advanced bypass techniques with user-friendly configuration options, it enables businesses to gather competitive intelligence and market insights efficiently.
Ready to unlock valuable data from Datadome-protected websites? Configure your scraper today and start extracting the insights your business needs to stay competitive in the digital marketplace.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about Datadome web Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.


